The novel satirizes a (badly written) science fiction TV show. Over time, the protagonist and some others become aware that
they are they are within that TV show, and that they must avoid The Narrative. The Narrative is most prevalent around
the bridge personnel of the spaceship. Unfortunately for the protagonist and their team, the bridge crew members carry plot armor,
a luxury not awarded to normal crew.
The novel is an amusing read, with a fun premise and good follow-through. I also liked the coda where the situation is looked
at from the perspective of the (bad) TV show writer and other people in the story.
While I got around to some programming and thinking, neither the thinking
nor the programming are done enough yet for a blog post, but here is an
image-in-progress that I drew in Inkscape:
I bought the game for 3€ in a Steam sale, and for that money it is well worth the time.
The game runs very smooth on a 16GB machine with an RTX 1080 card.
The Good
Story
Story is serviceable. The Bad Guy is Really Evil. You are the son of a resistance fighter in some random tibetan/nepalese/whatever country. Your mother
left for the US with you as a child, but for some reason still trained you to be a fighter. At least, nobody mentions or wonders why you are handy with all
those weapons that are lying around. Also, nobody asks
where you were or how your life was, but accepts you as the son of the former leader. The story sets you up in the game and is motivation for some of
the missions, and that's it. It is by lengths better than in Assassins Creed: Origins (the "Egypt" episode).
Gameplay
The gameplay is good. It is a typical UbiSoft game, with lots and lots of collectibles, but at least you can buy maps that list the collectible locations. The
fighting is good, despite the occasional QuickTime event.
The Bad
The intro is unskippable, which is highly inconvenient if the game crashes juuust before the end of the intro. Otherwise I haven't encountered
any bad bugs. The convenience of playing old games is that you get to play the best version there is. At least for offline games, where they
don't patch out songs from the soundtrack and so on.
The Ugly
The game is connected to the UbiSoft launcher, even when you buy it through Steam. That launcher updates itself every time you launch it through Steam. It also requires a (burner) email address for launching the game.
I should maybe start looking for a crack/patch that allows to remove the UbiSoft launcher by replacing it with a small program that mimics it but uses fewer resources.
At least Far Cry 4 does not have microtransactions.
Continuing my quest to using my Google Pixel 9 Pro Android phone as thin client in a docking station, with GrapheneOS build 2026062801, Android 17, previously Android 16.
Experience
With the 2026062801 build, you plug the phone into the docking station, select the display mode to extend the screen to the external display, and it just works. The mouse and keyboard input work anyway, and the phone asks you whether to connect the screen as a secondary display or to mirror the phone screen to the external display.
Improvements
The task bar on the external screen now works without alignment and mouse detection issues.
Opening an app to the big screen or moving it to the big screen now works by launching it from the big screen instead of mobile screen.
Opening the settings from the top pulldown menu on the external screen opens the settings on the small screen. Launching the settings app from the menu launches it on the external screen as it should.
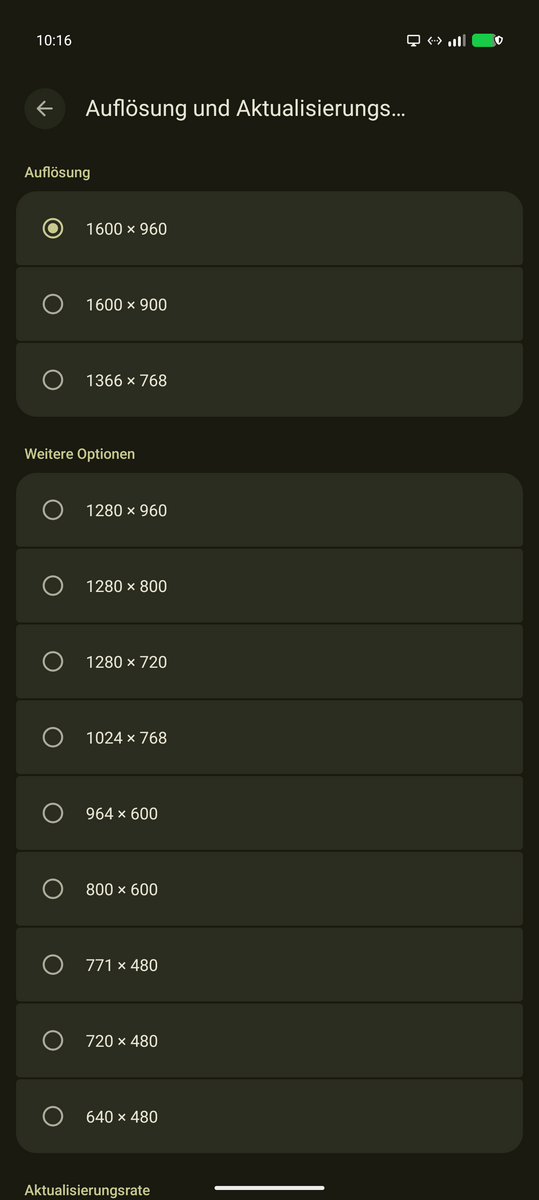
Screen dimensions can now be selected. Weirdly, on a 2560x1600 display, selecting
2560x1600 gave a crisp picture which still was constrained to a 1600x980 like
screen with black bars to the left and right. I assume that the external DP alt
mode has a limitation to 1600px width in data transfer. On my local 11" 4k
display, the different resolutions top out at 2048x1152. This is acceptable for
the size of the display, but I would still like to use a larger resolution.
Bluetooth audio output works, but the microphone remains mute.
Initially external cameras did not work inside the $work Citrix workspace app. They get shown by the app but don't show up in Teams. There was a permissions pop-up on the phone screen to allow the app access to the USB-connected external camera, after selecting the external
camera in the Citrix app menu. Allowing that permission via the phone screen made the camera usable within MS Teams on the remote end. The camera resolution seemed to be degraded, but that's maybe due to the Logitech 920c camera having a subpar UVC implementation?
USB and Thunderbolt cables
The orders for the various USB-C / USB-C cables arrived since the last
experiment, and the results vary, as seems to be expected with the new world
of basically indistinguishable cabling we live in.
The SUMPK cable has the mildly annoying disfeature that the display connection
is not necessarily detected as 1600x900 , but sometimes only as 1280x720. I
attribute this to the connection quality.
With the two Thunderbolt 5 "certified" cables, the display resolution gets
up to 2048x1152 , but the external display still retains the DPI scaling, so
the improvement in fidelity does not result in more information getting shown
on the screen.
At least I now have a set of cables that are known good cables for the phone
connection and I will bring such a cable with me for when I need to hook up
the phone to a docking station.
In the end, the phone is now a workable brain to use as a remote desktop client with Android 17.
I'm not really happy with using Claude Code as my coding harness. Not that I have spent much time in the last three months using the slopmachines, but as the GLM subscription is already paid for and GLM 5.2 just came out, I'm revisiting coding harnesses other than Claude Code, and here is my setup for running pi.dev in a Podman container.
Plugins
The agent now supports subagents and task lists via plugins. Obra's superpowers is indispensable to me.
Like all coding harnesses, pi.dev also uses a lot of blinking lights to keep the user entertained while they wait for tokens. I removed the background colors by editing ~/.pi/agent/settings.json:
{
"theme": "transparent"
}
And adding transparent.json to ~/.pi/agent/themes/transparent.json: