Who am I?

-
Max Maischein
-
DZ BANK Frankfurt
-
Deutsche Zentralgenossenschaftsbank
-
Information management
My Leitmotiv
Automation

-
If I can do it manually
-
... then the computer can repeat it
-
... correctly every time
My Environment
DZ BANK AG
Intranet web automation and scraping (WWW::Mechanize::Firefox)
My Environment
DZ BANK AG
Intranet web automation and scraping (WWW::Mechanize::Firefox)

-
People ask about web scraping
-
People ask about HTML parsing
Aspects of Web Scraping

Not everything that is technically possible is also allowed or desired
-
Can you avoid scraping?
1: Database Access 2: Database dump
-
Is scraping allowed?
1: Terms of Service (TOS) 2: TOS applicable?
Process

-
Identify the steps a human takes
-
->Navigation -
->Content Extraction -
Automate these steps
-
Repeat
Web Page

Web Page
Firebug

Firebug
-
Add-on for Firefox
-
Visual tool to inspect elements on the web page
Our goal
Extract news posts
First CSS selector
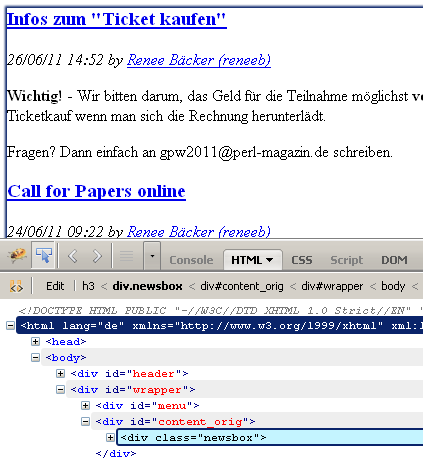
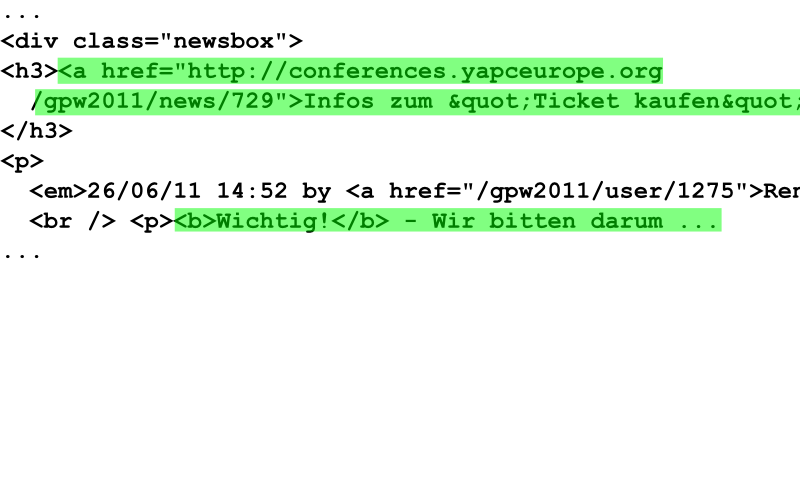
1: .newsbox
Refined CSS selector
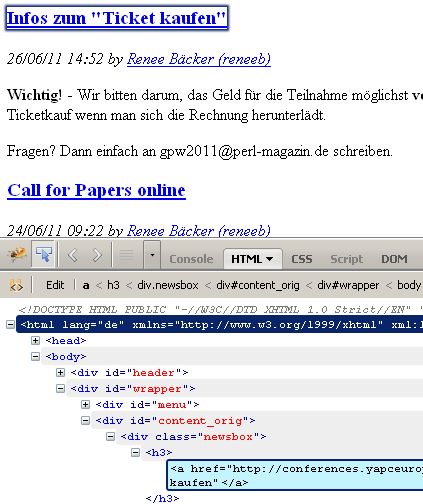
1: .newsbox h3 a
Refined CSS selector
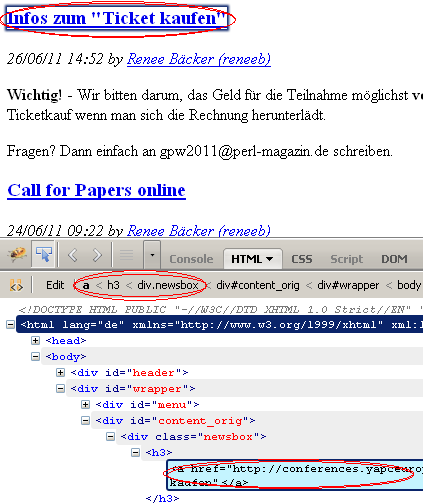
1: .newsbox h3 a
Refined CSS selector
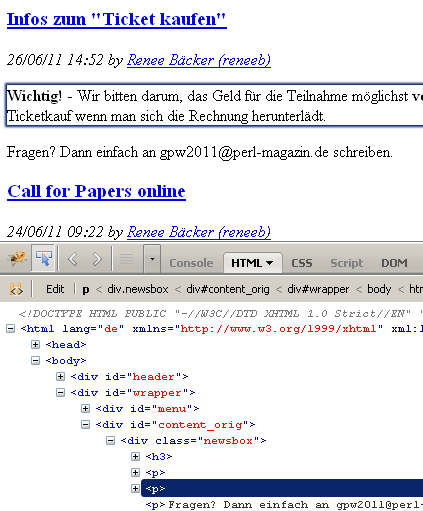
1: .newsbox h3 a 2: Call for Papers online
Refined CSS selector
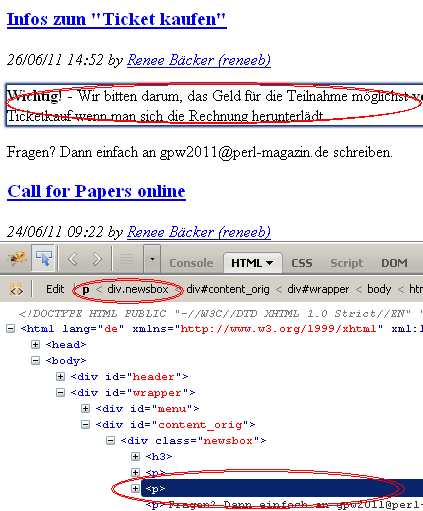
1: .newsbox h3 a 2: Call for Papers online 3: 4: .newsbox h3+p+p 5: Endlich ist es so weit ...
More Complex Example situation (Wikipedia)

-
Extract images of (DC) Super Heroes from Wikipedia
-
Input: Name of Super Hero
-
Output: Image URL (or data) of Super Hero Image on Wikipedia and description text
Fill in the field
-
Find the field
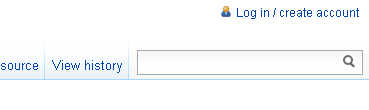
1: search
Fill in the field
-
Find the field
1: search
-
Find the field name
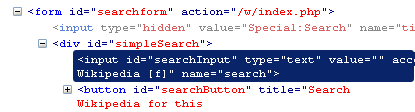
Fill in the field
-
Find the field
1: search
-
Find the field name
1: submit_form with_fields( {
2: search => $hero,
3: });
Find the image
-
Find the image selector (Firebug, ...)
1: .infobox a.image img
-
Extract it
1: print $_->{src} 2: for selector('.infobox a.image img'); 3: 4: # ttp://upload.wikimedia.org/wikipedia/en/thumb/7/72/Superman.jpg/250px-Superman.jpg
Example: Extracting Google+ profiles

-
Google+ is Google's (second attempt at a) social network
Steps
-
Search with Google for the name
-
Extract the information from the profile page
-
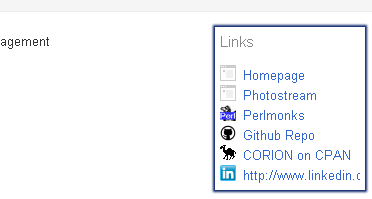
Extract "people in circles"
Web Page
1: <h2 class="a-b-D-Nd-aa d-q-p">Links</h2> 2: <ul class="a-b-D-G-lg Nd"> 3: <li><img alt="" class="a-b-D-Mf" src="113231249772841733835_files/favicons_007.png"> 4: <div class="a-b-D-k k"><a class="a-b-D-k-cg url" href="http://corion.net/" 5: ...
Find the related links
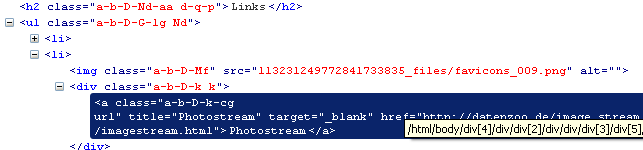
Find the related links
1: div.k a.url
2:
3: my @links = selector('div.k a.url');
4:
5: for my $link (@links) {
6: print $link->{innerHTML}, "\n";
7: print $link->{href}, "\n";
8: print "\n";
9: };
Find the "circled" contacts
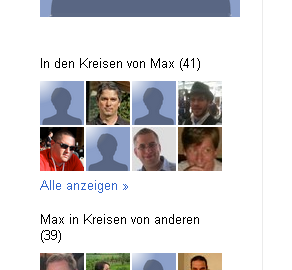
Find the "circled" contacts

Find the "circled" contacts
Google is heavily set on JSON / dynamic Javascript
1: var OZ_initData = 2: ... 3: ,""] 4: ,1,,1] 5: ,[[41,[["113771019406524834799","/113771019406524834799",...,"Paul Boldra"] 6: ,["101868469434747579306","/101868469434747579306",...,"Curtis Poe"] 7: ,["114091227580471410039","/114091227580471410039",...,"James theorbtwo Mastros"] 8: ,["116195765101222598270","/116195765101222598270",...,"Michael Kröll"] 9: ...
Find the "circled" contacts
Google is heavily set on JSON / dynamic Javascript
1: var OZ_initData = 2: ... 3: ,""] 4: ,1,,1] 5: ,[[41,[["113771019406524834799","/113771019406524834799",...,"Paul Boldra"]
We want
1: OZ_initData["5"][3][0]
Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules

Relevant Modules
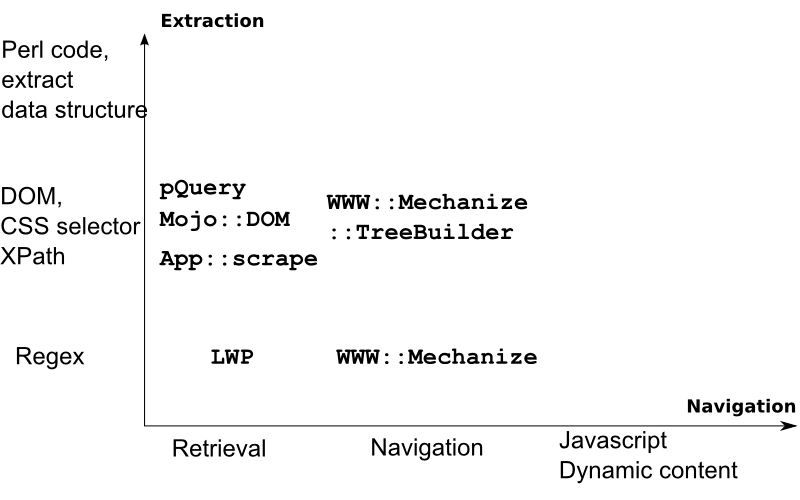
Relevant Modules
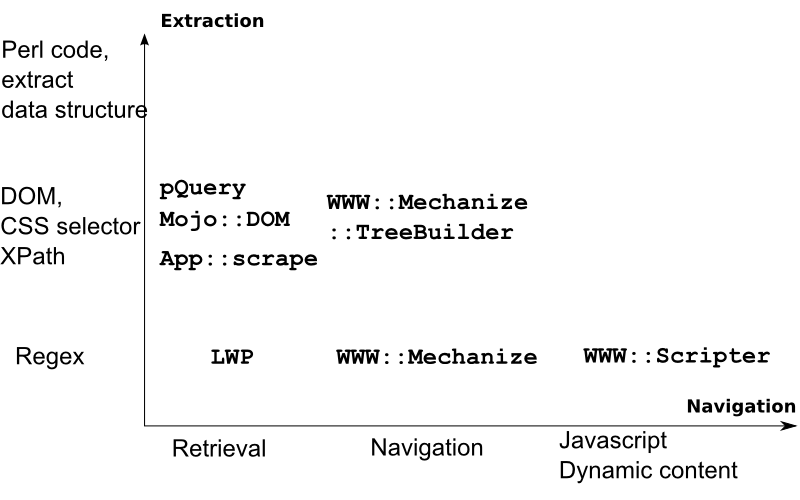
Relevant Modules
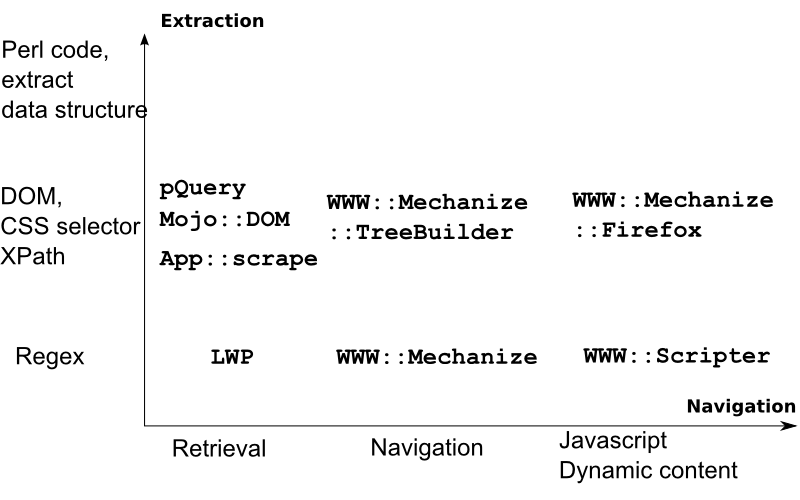
Relevant Modules

Relevant Modules

Writing your own scraper
Reuse the work of others
Tatsuhiko Miyagawa
-
HTML::Selector::XPath - use CSS3 selectors
-
HTML::AutoPagerize - walk through paged results