Perl f³r Fortgeschrittene

-
Weites Feld
-
Kleine Schritte
-
▄berblick ³ber Kenntnisse
-
▄berblick ³ber Techniken
-
▄berblick ³ber Anwendung
-
Einzelne Gebiete
Die Anwendung

User
Die Anwendung

Firefox-User
Die Anwendung
Firefox-User
Schnelle Downloads
Die Anwendung
Firefox-User
Schnelle Downloads
Langsame Uploads
Die Anwendung
Firefox-User
Schnelle Downloads
Langsame Uploads
Schnelle Downloads vom privaten Server
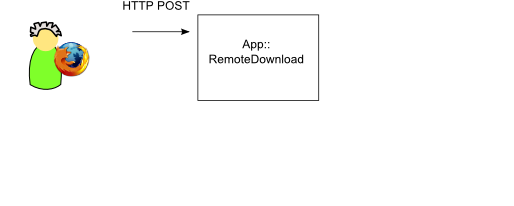
Projekt RemoteDownload

-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
Projekt RemoteDownload
-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen
Projekt RemoteDownload
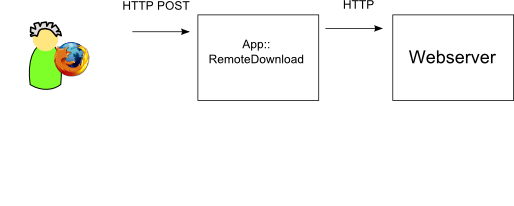
-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen -
wgetzum Download
Projekt RemoteDownload
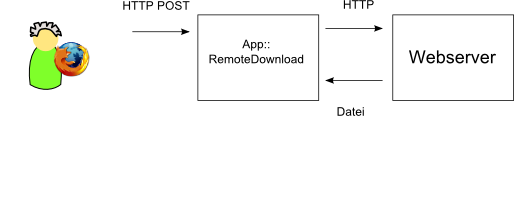
-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen -
wgetzum Download
Projekt RemoteDownload
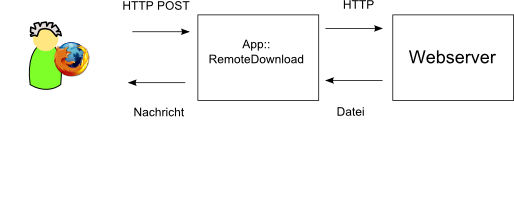
-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen -
wgetzum Download -
Einfaches HTML f³r die Fortschrittsanzeige
Projekt RemoteDownload

-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen -
wgetzum Download -
Einfaches HTML f³r die Fortschrittsanzeige
Frameworks

-
Frameworks sind mõchtig
-
Frameworks behindern das Verstõndnis
-
Daher: Keine Frameworks
Frameworks (2)

-
Nicht immer effizient (Templates)
-
Erstaunlicherweise klappt es
-
Flexibilitõt ist hilfreich und behindert (z.B.
DBIx::Class) -
CPAN-Release?
Referenzen

-
Eine Referenz ist immer ein Skalar
-
Referenzen sind wie eine Schnur - man hõlt das eine Ende und hat den Wert am anderen Ende
-
Bessere Metaphern sind willkommen
Symbolische Referenzen
Symbolische Referenzen sind Schn³re mit Namen
-
Gut bei eindeutigem Namen
-
Maximilian Johannes Maischein
-
Schlecht bei Allerweltsnamen
-
Ulli M³ller
-
Und Tippfehlern
-
Uli M³ller
Alternative zu symbolischen Referenzen

1: %messages = (
2: hallo => [],
3: );
4: $messages{hello}->[0] = 'World';
-
Sch³tzt nicht vor Tippfehlern
-
Sch³tzt vor unbeabsichtigten Datenlecks
Exkurs: Sichtbarkeit und Lebensdauer
Exkurs zu meinem letzten Tutorial (Bochum, 2006)

Sichtbarkeit und Lebensdauer
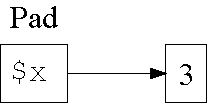
my erzeugt eine lexikalische Bindung ("binding")
eines Namens an einen Wert:
1: my $x = 3;
-
Bindung nur innerhalb von Sichtbarkeit
-
"Pad" speichert Bindungen
-
use strict;pr³ft Bindungen -
Lexikalische Bindungen (
my) -
Globale Bindungen (
use vars;)
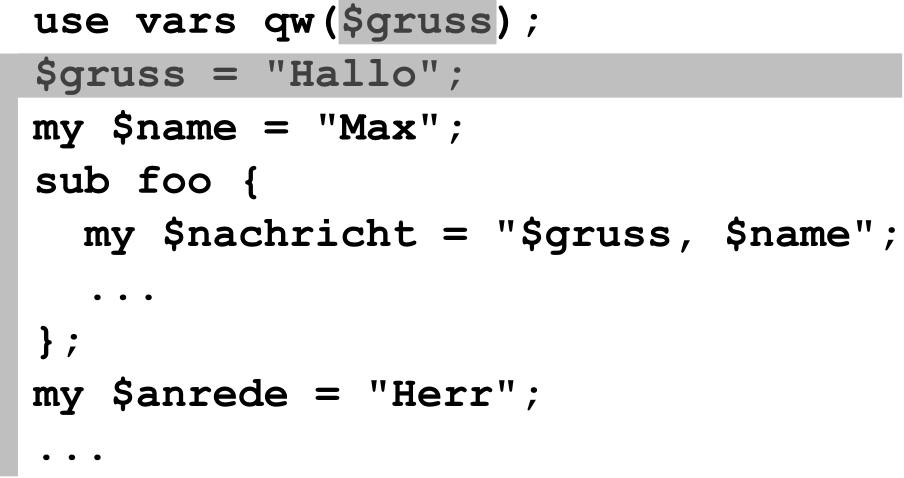
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:

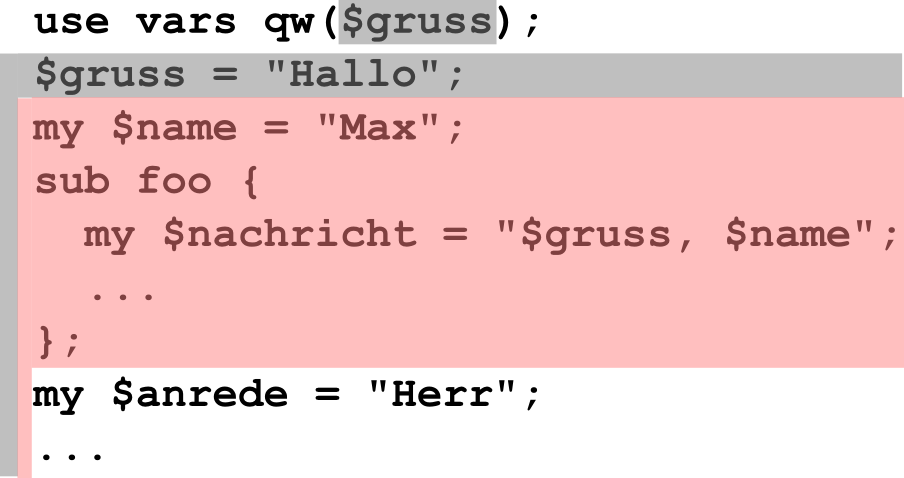
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:
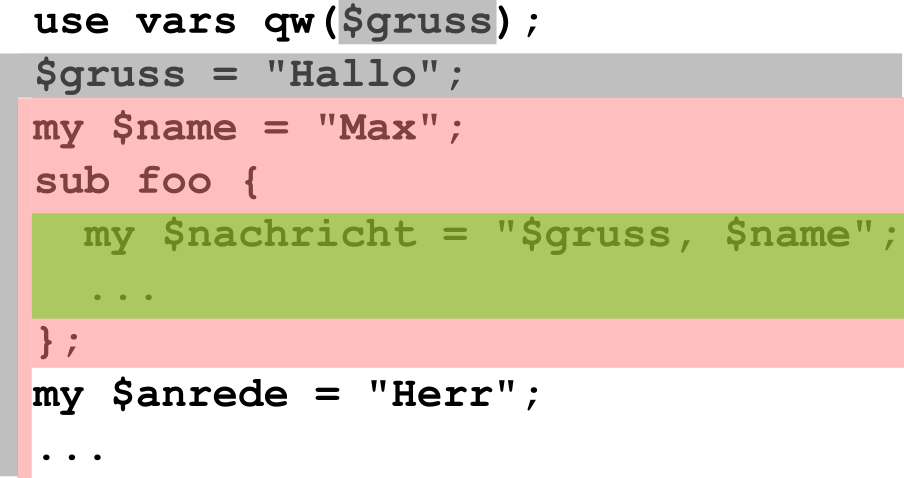
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:
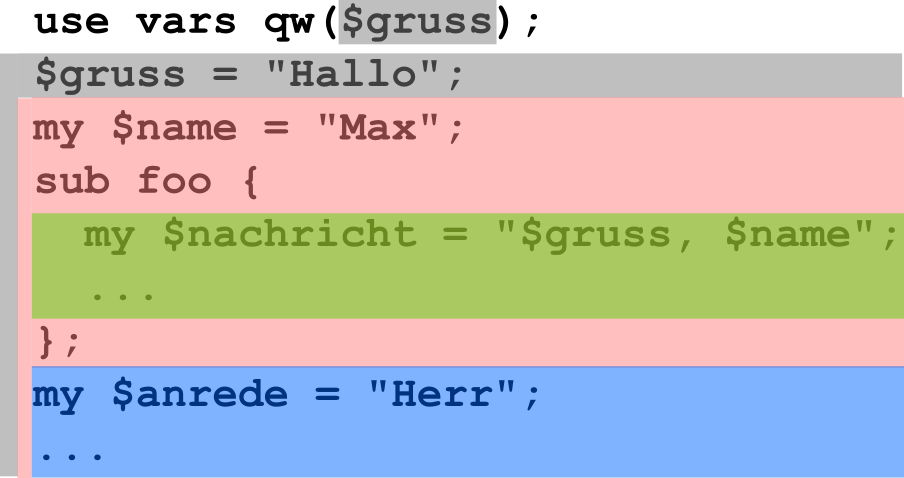
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:
Lebensdauer von Werten
-
Lebensdauer von Werten und Sichtbarkeit von Bindungen sind nicht das selbe.
-
Datenstruktur in Zeile 4:
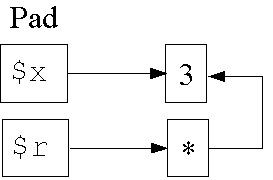
1: my $x; 2: { 3: $x = 3; 4: my $r = \$x; 5: } -
Lebensdauer und Sichtbarkeit stimmen ³berein.
Lebensdauer von Werten (I/2)
Datenstruktur in Zeile 5 (Zwischenschritt):
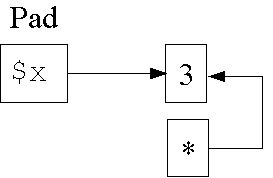
1: my $x;
2: {
3: $x = 3;
4: my $r = \$x;
5: }
Lebensdauer von Werten (I/3)
Datenstruktur in Zeile 5:
1: my $x;
2: {
3: $x = 3;
4: my $r = \$x;
5: }
Lebensdauer von Werten (II/1)
Datenstruktur in Zeile 4:
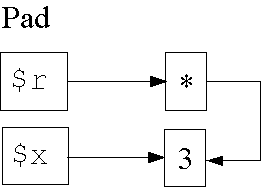
1: my $r;
2: {
3: my $x = 3";
4: $r = \$x;
5: }
Lebensdauer von Werten (II/2)
Datenstruktur in Zeile 5:
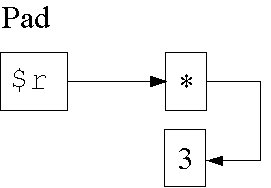
1: my $r;
2: {
3: my $x = 3";
4: $r = \$x;
5: }
-
Lebensdauer und Sichtbarkeit stimmen nicht ³berein.
-
Der Wert
3lebt weiter
Queue SQL - Update

Queue SQL - Update

Queue SQL - Update

Queue SQL - Update

Queue SQL - Update

Queue SQL - Update

Queue SQL - Select
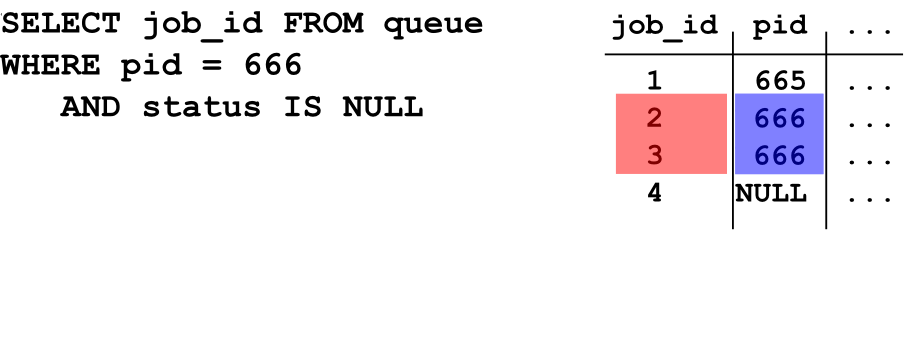
Queue SQL - Select

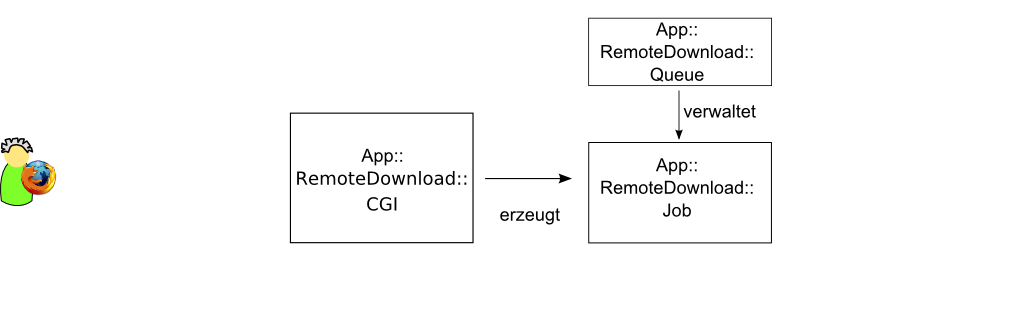
▄berblick ³ber Webserver

▄berblick ³ber Webserver
▄berblick ³ber Webserver
▄berblick ³ber Webserver
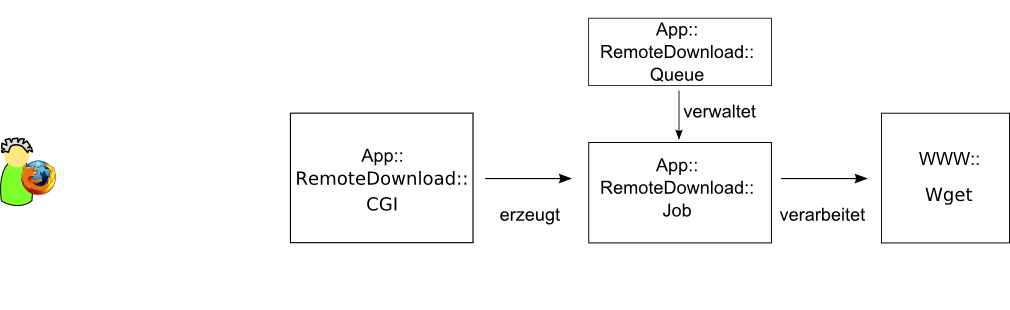
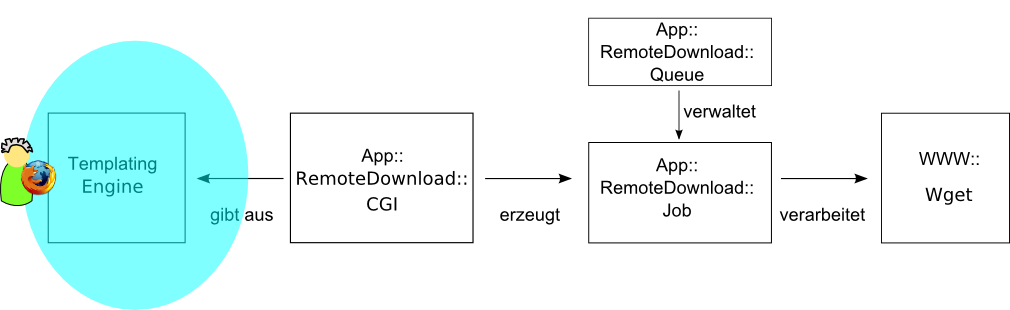
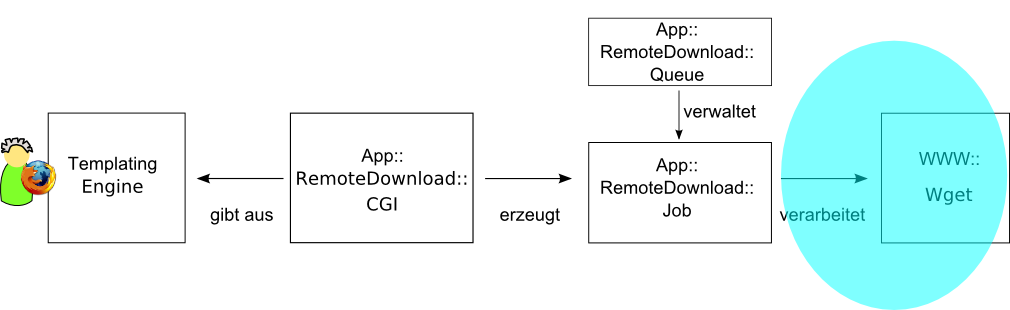
Das Webinterface
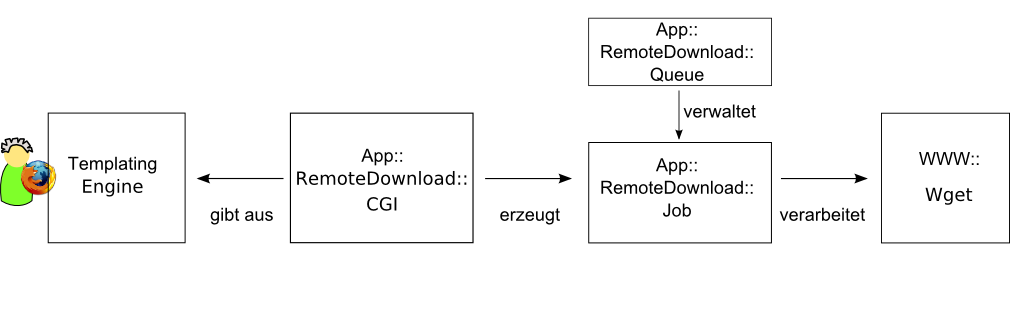
Das Webinterface
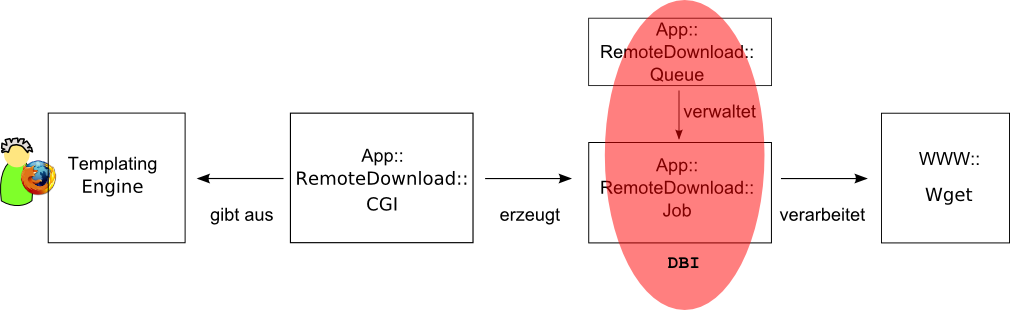
Das Webinterface
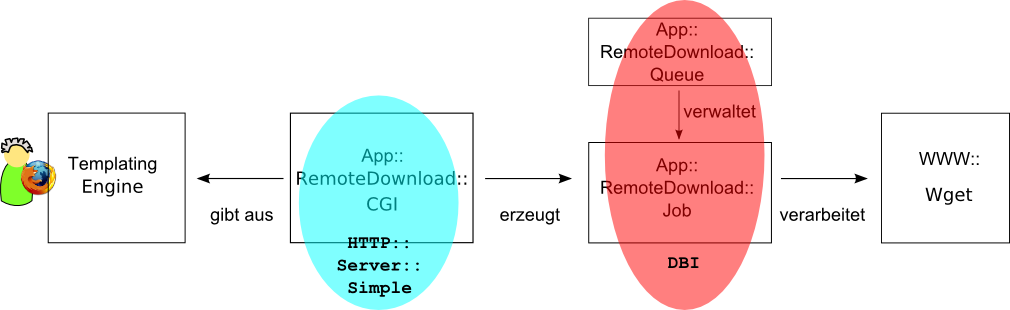
Das Webinterface
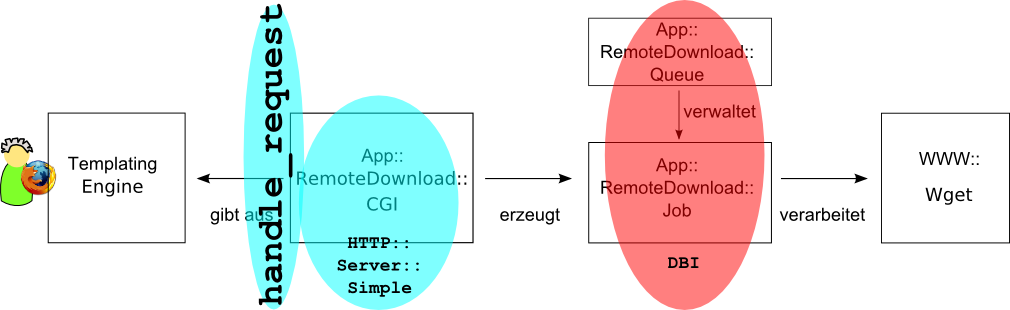
Zentrale Behandlungsroutine handle_request
Dispatch ³ber if
1: package App::RemoteDownload::CGI;
2: sub handle_request {
3: my ($self,$cgi) = @_;
4:
5: my $p = $cgi->query_path;
6: if ($p =~ m!^/!) {
7: $self->index();
8: } elsif ($p =~ m!^/submit!) {
9: ...
10: }
11: }
-
Schwer zu warten und zu konfigurieren.
Dispatch Tabellen

-
Zuordnung von URL und Code in Hash
Ausgabe in HTML
-
Meine eigene Templating Engine
Meine eigene Templating Engine
Darstellung der Job-Queue f³r einen User:

Templates (print)
Darstellung der Job-Queue f³r einen User:
Erste L÷sung - direkte Stringausgabe
1: print "<html>...</html>";
Templates (CPAN)
Zweite L÷sung - CPAN Module
Templates ³ber HTML::Template, Template Toolkit etc.
Templates (Eigene Engine)

Dritte L÷sung - die eigene Templating Engine
Templates (Eigene Engine)
Dritte L÷sung - die eigene Templating Engine
Syntax:
1: $user # $user
2: $hash.key # $hash->{key}
Templates (Eigene Engine)
Dritte L÷sung - die eigene Templating Engine:
Syntax:
1: $user # $user
2: $hash.key # $hash->{key}
Listen
1: [% START jobs %] 2: $job_id | $url | $status 3: [% END jobs %]
Templates (Eigene Engine)
Dritte L÷sung - die eigene Templating Engine:
Syntax:
1: $user # $user
2: $hash.key # $hash->{key}
Listen
1: [% START jobs %] 2: $job_id | $url | $status 3: [% END jobs %]
Die Listensyntax ist ³bernommen von Template::Simple
Implementation
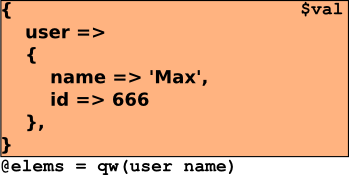
1: sub dive {
2: my ($path,$parameters) = @_;
3: my @elems = split /\./, $path;
4: my $val = $parameters;
5: for (@elems) {
6: $val = $val->{$_};
7: }
8: $val
9: }
Implementation
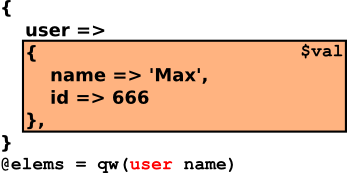
1: sub dive {
2: my ($path,$parameters) = @_;
3: my @elems = split /\./, $path;
4: my $val = $parameters;
5: for (@elems) {
6: $val = $val->{$_};
7: }
8: $val
9: }
Implementation
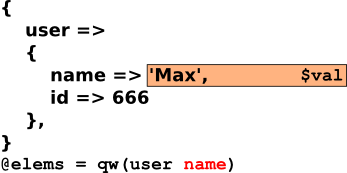
1: sub dive {
2: my ($path,$parameters) = @_;
3: my @elems = split /\./, $path;
4: my $val = $parameters;
5: for (@elems) {
6: $val = $val->{$_};
7: }
8: $val
9: }
Templating Systeme

Templating Systeme Eigenbau

Templating Systeme print

Templating Systeme Template::Simple

Templating Systeme HTML::Template

Templating Systeme HTML::Template::Compiled

Templating Systeme Petal

Templating Systeme Template::Toolkit

Templating Systeme Text::Template

Templating Systeme Mason

Atempause
-
Ist das sinnvoll?
-
Nein, vorgefertigte L÷sung
-
Ja, gut zu wissen
Tests von erweiterter IPC
Tests von erweiterter IPC
WWW::Wget
▄berwachung der Queue

-
Queue lõuft
-
User haben Fragen
-
Schnell Abfragen erstellen
Querylet
1: #!/usr/bin/perl -w 2: use strict; 3: use Querylet; 4: 5: database: dbi:SQLite:dbname=r...d.sqlite 6: 7: # User mit der gr÷ssten Downloadmenge 8: query: 9: SELECT owner, count(*), sum(size) 10: FROM queue 11: WHERE pid is NULL 12: GROUP BY owner 13: ORDER BY sum(size) 14: 15: output format: html 16: output file: statistik.html
Querylet (Ausgabe)
Statistik.html

Wie funktioniert Querylet

-
Querylet ist ein Source-Filter.
-
Source Filter sind gefõhrlich
-
Source Filter sind ungeheuer praktisch
Foto: pdcawley
Verwenden von Filter::Simple

-
Suchen und Ersetzen ist schwierig
-
Fehlermeldungen sind kryptisch (
//) -
Unangenehme Seiteneffekte
-
Acme::Bleach
Module

-
AtExit
-
Hook::Scope
-
Perl::AtEndOfScope
-
Scope::Guard
-
Hook::LexWrap
-
Object::Destroyer